
C-READ System, climate change monitoring with GeoNode and CKAN
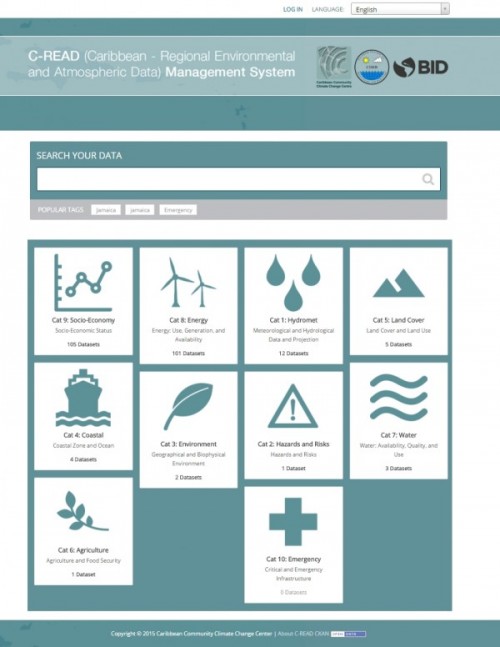
The C-READ system has been developed by GeoSolutions for the Caribbean Community Climate Change Centre (CCCCC or 5Cs) leveraging on several Open Source components (CKAN, GeoNode, GeoServer, QGIS and Jenkins) to provide SDI functionalities for climate change monitoring, allowing scientistis and users in the caribbean area to upload and fuse historycal as well as near real-time data in a single instructure. You can read the full story in our portfolio at this link.
If you want to know more about how we can help your organization, don’t hesitate and get in touch with us! Make sure to check out Enterprise Services Offer, we give away discounted prices until end of January 2016!
The GeoSolutions Team,
